faster-eTaPR#
![]()

![]()
![]()
Faster implementation (~200x) of the enhanced time-aware precision and recall (eTaPR) from Hwang et al. The original implementation is saurf4ng/eTaPR and this implementation is fully tested against it.
Motivation#
The motivation behind the eTaPR is that it is enough for a detection method to partially detect an anomaly segment, as along as an human expert can find the anomaly around this prediction. The following illustration (a recreation from the paper) highlights the four cases which are considered by eTaPR:
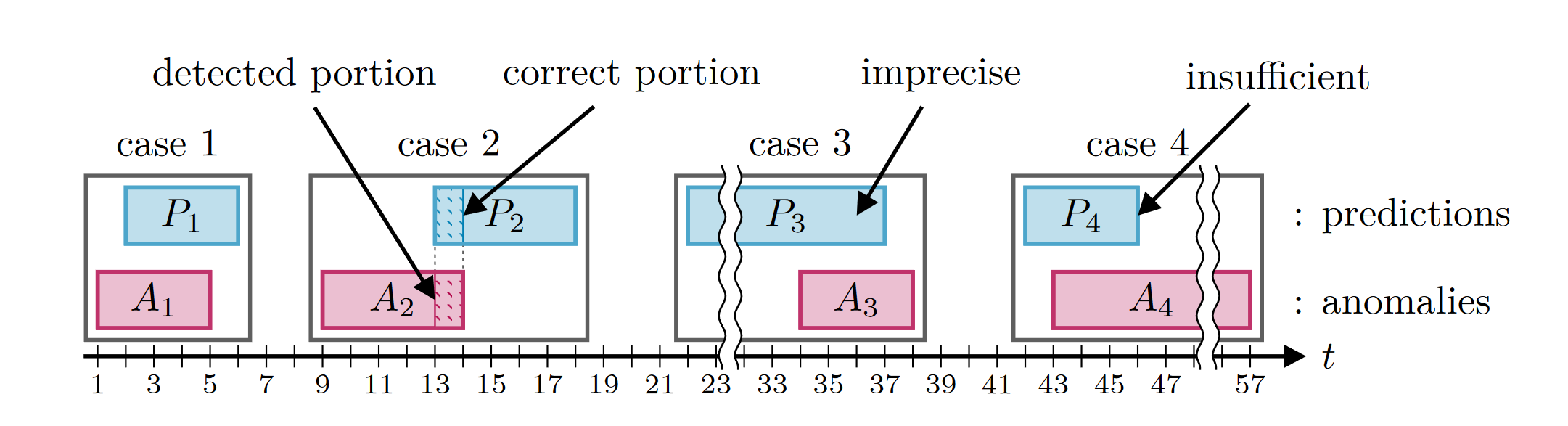
A successful detection: A human expert can likely find the anomaly \(A_1\) based on the prediction \(P_1\).
A failed detection: Only a small portion of the prediction \(P_2\) overlaps with the anomaly \(A_2\).
A failed detection: Most of the prediction \(P_3\) lies in the range of non-anomalous behavior (prediction starts too early). A human expert will likely regard the prediction \(P_3\) as incorrect or a false alarm. The prediction \(P_3\) is too imprecise and the anomaly \(A_3\) is likely to be missed.
A failed prediction: The prediction \(P_4\) mostly overlaps with the anomaly \(A_4\), but covers only a small portion of the actual anomaly segment. Thus, a human expert is likely to dismiss the prediction \(P_4\) as incorrect because the full extend of the anomaly remains hidden. The prediction P_4 contains insufficient information about the anomaly.
Note that for case 4, we could still mark the anomaly as detected, if there were more predictions which overlap with the anomaly \(A_4\). Specifically, the handling of the cases 3 and 4 is what sets eTaPR apart from other scoring methods.
If you want an in-depth explanation of the calculation, check out the documentation.
Getting Started#
Install this package from PyPI using pip or uv:
pip install faster-etapr
uv pip install faster-etapr
Now, you run your evaluation in python:
import faster_etapr
faster_etapr.evaluate_from_ranges(
y_hat=[0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0],
y= [0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1],
theta_p=0.5,
theta_r=0.1,
)
{
'eta/recall': 0.3875,
'eta/recall_detection': 0.5,
'eta/recall_portion': 0.275,
'eta/detected_anomalies': 2.0,
'eta/precision': 0.46476766302377037,
'eta/precision_detection': 0.46476766302377037,
'eta/precision_portion': 0.46476766302377037,
'eta/correct_predictions': 2.0,
'eta/f1': 0.4226312395393011,
'eta/TP': 4,
'eta/FP': 5,
'eta/FN': 7,
'eta/wrong_predictions': 2,
'eta/missed_anomalies': 2,
'eta/anomalies': 4,
'eta/segments': 0.499999999999875,
'point/recall': 0.45454545454541323,
'point/precision': 0.5555555555554939,
'point/f1': 0.49999999999945494,
'point/TP': 5,
'point/FP': 4,
'point/FN': 6,
'point/anomalies': 4,
'point/detected_anomalies': 3.0,
'point/segments': 0.75,
'point_adjust/recall': 0.9090909090909091,
'point_adjust/precision': 0.7142857142857143,
'point_adjust/f1': 0.7999999999995071
}
We calculate three types of metrics:
the enhanced time-aware (eTa) metrics under
eta/the (traditional) point-wise metrics under
point/the point-adjusted metrics under
point_adjust/
Benchmark#
A little benchmark with randomly generated inputs (np.random.randint(0, 2, size=size)):
size |
eTaPR_pkg |
faster_etapr |
factor |
|---|---|---|---|
1 000 |
0.4090 |
0.0032 |
~125x |
10 000 |
35.8264 |
0.1810 |
~198x |
20 000 |
148.2670 |
0.6547 |
~226x |
100 000 |
too long |
55.04712 |